| Главная » Статьи » Студентам » Бизнес-аналитика |
Анализ коротких сообщений в Twitter на основе RПакеты (расширения)Для работы понадобятся следующие расширения:
Регистрация в Twitter и доступ к APIЕсли у Вас нет аккаунта, Вам следует зарегистрироваться. Руководствуясь статьями по приведенным ниже ссылкам, получить доступ к API. r-analytics.blogspot.co.ke Подключение к TwitterВам нужно взять свои значения для consumerKey() и consumerSecret() на подобии и запустить setup_twitter_oauth()
> consumerKey<-"55ZCRbatWWVYpr2VU9Ddk1234"
> consumerSecret<-"ji4Zqit6jL7iIoegHKr3zVBoCTEeYSnmH0aAJdm3j3gRZRFlL7"
> setup_twitter_oauth(consumer_key=consumerKey,consumer_secret=consumerSecret)
Поиск коротких сообщений (твитов)Чтобы найти желаемое количество коротких сообщений, пусть 250 шт., содержащих ключевое слово или фразу – “business analytics” – воспользуемся функцией searchTwitter().
> tweets1 <- searchTwitter("business analytics", n=250)
> tweets2 <- searchTwitter("business analytics", n=250, lang="en", since="2014-01-01", resultType="popular")
> tweets3 <- searchTwitter("business analytics", n=250, lang="en", since=as.character(Sys.Date()))
> tweets4 <- userTimeline("krav", n=100)
> length(tweets1); length(tweets2); length(tweets3); length(tweets4)
[1] 250
[1] 19
[1] 250
[1] 100
Краткая информация об используемой функции: searchTwitter() – функция поиска сообщений в Твиттере с заданным поисковым текстом и максимальным количеством требуемых сообщений. «+» используется для разделения поисковых термов. lang – по умолчанию этот аргумент равен NULL, но используя коды ISO 639-1 можно ограничить твиты (короткие сообщения) по языку. since – ограничивает выборку твитов с заданной даты, формат которой YYYY-MM-DD Дополнительные примеры: Анализируемые данные представляют собой текстовый массив, содержащий информацию об отправителе, дате, времени и текст сообщения. Чтобы посмотреть, к примеру, 5-ю строку массива tweets1, введем
> tweets1[[5]]
[1] "INSPEC2T: On Easter Friday read our new #blog article by @imctechnologies on #business intelligence & #analytics in @INSPEC2T https://t.co/ypnLwE5wew"
Обратите внимание, что величина tweets4 определяется через функцию userTimeLine(). Она используется для получения последних публикаций на микроблоге конкретного пользователя.
Ниже приведен 3-й на текущий момент твит аккаунта Twitter с именем @krav, который содержится в tweets4.
[[3]]
[1] "krav: Book: Machine Learning Algorithms From Scratch | #BigData #MachineLearning... https://t.co/o8erHJxt3S by… https://t.co/RduHE1hJtj"
Twitter листы в таблицу данныхС помощью twListToDF() преобразуем twitter листы в таблицу данных (data frame). dataN <- twListToDF(tweetsN) N.B. Здесь и далее будем использовать N вместо числа в величинах tweets1, …, tweets4, т.е. в качестве номера (индекса): N = 1, …, 4. Так выглядят первые 3 строки в таблице data1, при этом на экран выведены только 1-й, 5-й и 13-й столбцы
> head(data1[c(1,5,13)],3)
text
1 RT @jminguezc: A Guide to Delivering and Implementing a Successful #BI Strategy. #BigData #DataScience #Analytics #DataViz\nhttps://t.co/DNQ…
2 RT @seovalencia: How Big data analytics can help your eCommerce business - by @gloria_kopp https://t.co/jsDiy0SPzc #BigData
3 RT @jminguezc: A Guide to Delivering and Implementing a Successful #BI Strategy. #BigData #DataScience #Analytics #DataViz\nhttps://t.co/DNQ…
created isRetweet
1 2017-04-14 12:00:37 TRUE
2 2017-04-14 12:00:17 TRUE
3 2017-04-14 12:00:14 TRUE
Графики динамики и распределения твитов в TwitterОдним из способов увидеть таблицу данных является функция View()
> View(data2)
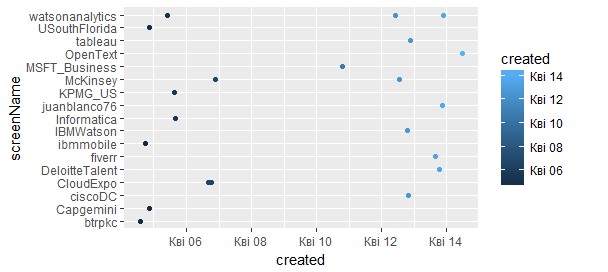
В таблице данных “data2” находятся самые популярные твиты с фразой “business analytics”. Получим график распределения твитов по времени и пользователям (аккаунту), опубликовавшим их. Результат виден на рис. 1.
> qplot(created, screenName, data = data2, colour = created)
Кроме того, распределение твитов можно смотреть, указывая фильтры, например, по числу повторных публикаций (“retweet”), как показано на рис. 2.
> qplot(created, data = data4, geom = "bar",weight= retweetCount)
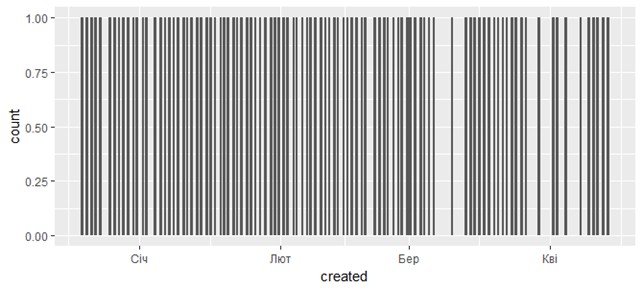
Рис. 2. Распределение твитов по числу retweet (на основе таблицы data4) Подключим библиотеку Построим график динамики коротких сообщений с фразой “business analytics”, полученных в tweets1 (рис. 3). Для этого применим ggplot() и geom_bar().
> cc1 <- ggplot(data1, aes(created))
> cc1 + geom_bar()
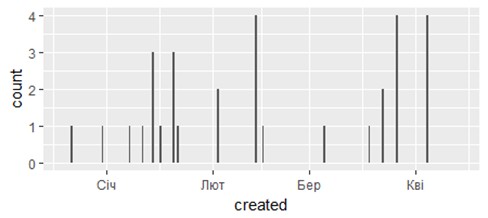
Рис. 3. Распределение твитов с фразой “business analytics”, полученных в tweets1 (таблица data1) Аналогично, динамика 100 последних публикаций в twitter.com/krav по дням изображена на рис. 4.
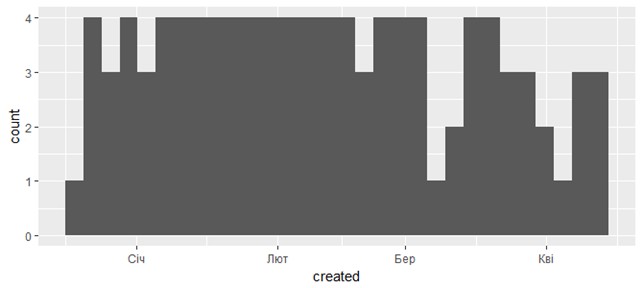
Рис. 4. Распределение по дням твитов в twitter.com/krav, полученных в tweets4 На основе tweets4 (таблица data4) построена также гистограмма (рис. 5), которая подсчитывает число случаев для каждой даты (каждой позиции x) без группировки (without binning). По умолчанию число интервалов берется равным 30 (bins = 30). Устанавливая параметры “bins” или “binwidth” в функции geom_histogram(), можно получить гистограмму с разным числом интервалов.
> cc4 <- ggplot(data4, aes(created))
> cc4 + geom_histogram()
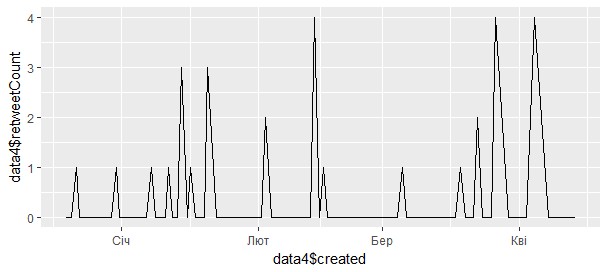
Рис. 5. Гистограмма твитов в twitter.com/krav, полученных в tweets4 На рис. 6 показано, когда и сколько ретвитов было в микроблоге пользователя @krav
> ggplot(data4, aes(data4$created,data4$retweetCount)) + geom_line()
Рис. 6. Динамика ретвитов по таблице данных data4 (twitter.com/krav) Маркировка (Label) твитаКаждому твиту присвоим метку времени (час), когда он был создан, порядкового номера месяца и номера дня недели, а также – года.
> dataN$month<-sapply(dataN$created, function(x) {p=as.POSIXlt(x);p$mon})
> dataN$hour<-sapply(dataN$created, function(x) {p=as.POSIXlt(x);p$hour})
> dataN$wday<-sapply(dataN$created, function(x) {p=as.POSIXlt(x);p$wday})
> dataN$year<-sapply(dataN$created, function(x) {p=as.POSIXlt(x);p$year})
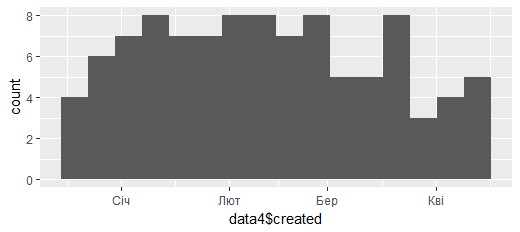
Дополнительные диаграммы на основе ggplotДля получения такой же диаграммы как на рис. 7, но с 16 интервалами, можно воспользоваться записью
> ggplot(data4, aes(data4$created)) + geom_histogram(bins=16)
Рис. 7. Диаграмма числа твитов на основе метки data4$created и bins=16 Диаграмма (рис. 8) числа твитов в зависимости от дня недели может быть получена следующим образом
> ggplot(data2,aes(x=wday))+geom_histogram(aes(y = (..count..)),binwidth = 1)
Рис. 8. Число твитов в зависимости от дня недели (для таблицы data2) Если требуется дать заголовок диаграмме, тогда следует воспользоваться ggtitle()
> ggplot(data4,aes(x=wday))+geom_histogram(aes(y = (..count..)),binwidth = 1) + ggtitle(paste("Weekday Tweets for @", data4$screenName[1], sep=" "))
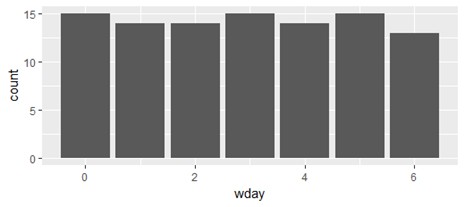
Для построения столбиковой диаграммы твитов по дням недели (рис. 9) можно выполнить
> ggplot(data4)+geom_bar(aes(x=wday))
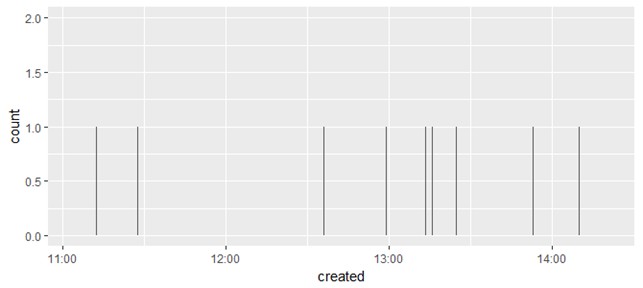
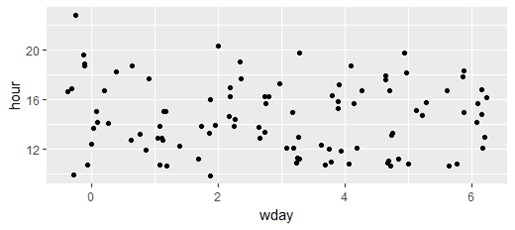
Рис. 9. Столбиковая диаграмма твитов по дням недели (twitter.com/krav) Для того, чтобы построить график коротких сообщений в зависимости от номера дня недели и часа (рис. 10), выполняется следующая команда
> ggplot(data4)+geom_jitter(aes(x=wday,y=hour))
Рис. 10. Твиты в зависимости от дня недели и времени (twitter.com/krav) Облако словПодготовка текстаНапомним, что N=1,2,3,4 – соответствует число в величинах tweets1, …,tweets4, data1, …, data4 и т.д. К каждому твиту применим функцию выделения текста:
> textN <- sapply(tweetsN, function(x) x$getText())
> text1[[1]]
[1] "Trying to optimize displays for footfall traffic? Learn about WiFi, Big Data & analytics in this webinar https://t.co/XNsr14obDX #retailtech"
Весь текст прописными буквами
> textN <- tolower(textN)
> text4[[1]]
[1] "habits to help you develop mental strength https://t.co/fidijeybkh #leadership by #wef via @c0nvey https://t.co/7tqgk4inmi"
Текст без пустых мест Текст без имен пользователей (@UserName) [1] "habits to help you develop mental strength https://t.co/fidijeybkh #leadership by #wef via https://t.co/7tqgk4inmi" Убрать пунктуацию [1] "habits to help you develop mental strength httpstcofidijeybkh leadership by wef via httpstco7tqgk4inmi" Убрать ссылки
> textN <- gsub("http\\w+", "", textN)
> text1[[1]]
[1] "habits to help you develop mental strength leadership by wef via "
Без табуляции
> textN <- gsub("[ |\t]{2,}", "", textN)
Убрать пустые места в начале и в конце сообщений
> textN <- gsub("^ ", "", textN)
> textN <- gsub(" $", "", textN)
> text4[[1]]
[1] "habits to help you develop mental strengthleadership by wef via"
Построение облака словПостроим облако слов (рис. 11) с использованием функции wordcloud()
> wordcloud(textN, min.freq = 1, scale=c(7,0.5), colors=brewer.pal(8, "Dark2"), random.color= TRUE, random.order = FALSE, max.words = 150)
Рис. 11. Облако слов для каждого варианта поиска коротких сообщений Создание Corpus. Матрица индексируемых слов с устранением нежелательных слов (stopwords)Создадим корпус текстовых сообщений, применяя Corpus()
> corpN <- Corpus(DataframeSource(data.frame(textN)))
Определим слова, которые не должны отображаться на облаке слов. При этом включаем, как стандартные наборы общих (нежелательных) слов через stopwords() для английского и русского языков, так и свои
> my.stopwords <-c("based", "via","bbfinale", "now", "rthappy", stopwords("english"), stopwords("russian"))
Преобразуем "корпус" в матрицу индексируемых слов из сообщений, устраняя stopwords
> dtmN <- TermDocumentMatrix(corpN, control = list(removePunctuation = TRUE, removeNumbers = TRUE, stopwords = my.stopwords))
Анализ матрицы индексируемых словfindFreqTerms() находит слова, которые встречаются не менее заданного числа раз
> findFreqTerms(dtm4, lowfreq=10)
[1] "big" "data" "ronaldvanloon" "science"
findAssocs() устанавливает ассоциации одного или нескольких терминов (текстового вектора) с другими терминами при условии минимальной силы связи (корреляции)
> findAssocs(dtm2, 'analytics', 0.30)
$analytics
bigdata iot
0.35 0.35
Построение облака слов на основе матрицыНа основе полученных ранее матриц dtmN зададим обычные матрицы
> m1 <- as.matrix(dtm1)
Изучая представленную ниже часть матрицы m1, можно понять ее общую структуру
> m1[20:25,1:4]
Terms Docs 1 2 3 4 analysis 0 0 0 1 analyst 0 0 0 0 analystanalytics 0 0 0 0 analyston 0 0 0 0 analytics 1 1 1 1 Функция dim() вычисляет размер матрицы (число строк и число столбцов)
> dim(m1)
[1] 723 250
Далее получаем числовой вектор, состоящий из сумм по строкам матрицы m1, и расположеных в порядке убывания – sort()
> v1 <- sort(rowSums(m1),decreasing=TRUE)
За вычисление сумм по строкам отвечает rowSums() analysis 4 analyst 1 analystanalytics 1 analyston 1 analytics 153 В итоге получаем
> v1[1:5]
analytics business data big bigdata
153 142 62 32 26
Создаем таблицу данных
> dN <- data.frame(word = names(vN),freq=vN)
> head(d1, 5) # или d1[1:5,]
word freq
analytics analytics 153
business business 142
data data 62
big big 32
bigdata bigdata 26
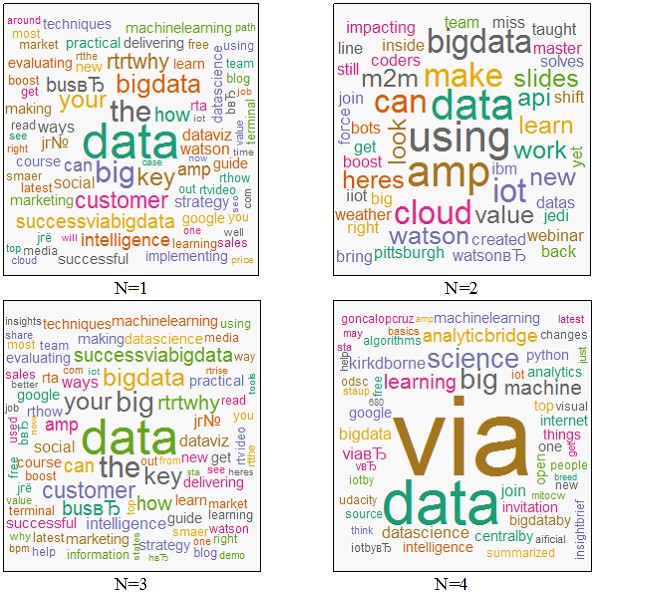
Наконец, переходим к созданию облака слов на основе функции wordcloud() для всех запросов в Twitter N (рис. 12). Вариант 1. Первый вариант команды имеет вид
> wordcloud(dN$word, dN$freq, random.order=FALSE, colors=brewer.pal(8,"Dark2"))
Рис. 12. Облака слов (word-cloud): вариант 1 для всех запросов поиска N Другие варианты построения.Вариант 2. Wordcloud для запроса N=2 показано на рис. 13. Он получен путем выполнения
> wordcloud(words = dN$word, freq = dN$freq, min.freq = 1,
+ max.words=100, random.order=FALSE, rot.per=0.35,
+ colors=brewer.pal(6, "Paired"))
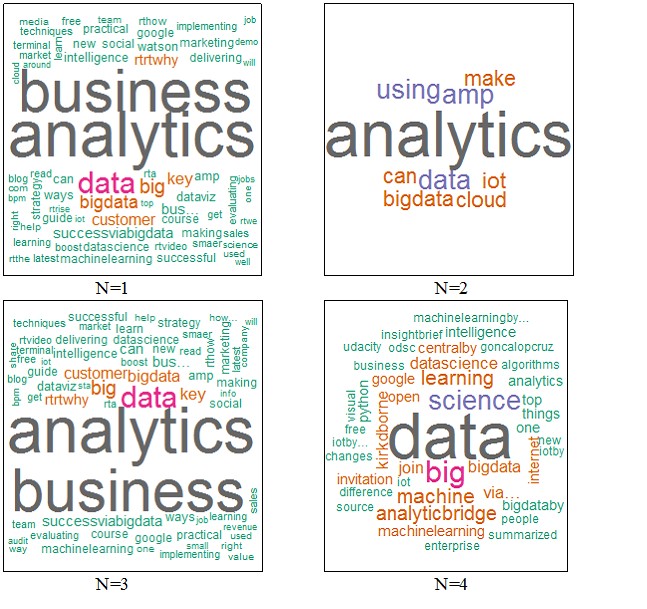
Рис. 13. N=2 Вариант 3 (см. рис. 14).
> wordcloud(words = dN$word, freq = dN$freq, min.freq = 3,
+ max.words=200, random.order=FALSE, rot.per=0.35,
+ colors=brewer.pal(7, "BrBG"))
Рис. 14. N=3
> wordcloud(words = d4$word, freq = d4$freq, min.freq = 3,
+ max.words=200, random.order=FALSE, rot.per=0.35,
+ colors=brewer.pal(9, "Set1"))
Рис. 15. N=4 Еще несколько примеров: Вариант 5.
> wordcloud(names(v1), v1^0.3, scale=c(2,0.3),random.order=F, colors="black")
> wordcloud(names(v2), v2^0.4, scale=c(5,0.3),random.order=F, colors="blue4")
> wordcloud(names(v3), v3^0.5, scale=c(1,0.6),random.order=F, colors="deeppink4")
> wordcloud(names(v4), v4^0.8, scale=c(2,0.5),random.order=F, colors="violet")
Вариант 6.
> wordcloud(d1$word, d1$freq, colors = brewer.pal(8, "Accent"))
> wordcloud(d2$word, d2$freq, colors = brewer.pal(8, "Blues"))
> wordcloud(d3$word, d3$freq, colors = brewer.pal(9, "Spectral"))
> wordcloud(d4$word, d4$freq, colors = brewer.pal(10, "RdYlBu"))
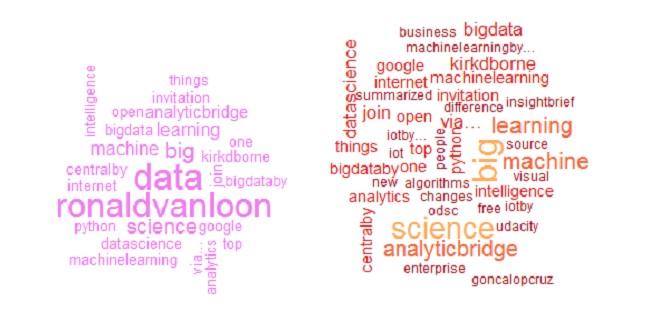
Для последней записи и в 5-м, и в 6-м вариантах облако слов имеет вид, как показано на рис. 16.
Рис. 16. Word-cloud для запроса в N=4 Матрицу индексируемых слов (dtmN) можно очистить от слов с низкой частотой появления. Аргумент sparse в функции removeSparseTerms() устанавливается от 0 до 1. Листинг получения новой таблицы данных на основе dtm1 посредством применения removeSparseTerms():
> dtm1s<-removeSparseTerms(dtm1,.95)
> m1s <- as.matrix(dtm1s)
> v1s <- sort(rowSums(m1s),decreasing=TRUE)
> d1s <- data.frame(word = names(v1s),freq=v1s)
В итоге получено новое облако слов (рис. 17)
Рис. 17. Облако слов для N=1 после выполнения removeSparseTerms() Диаграммы наиболее частых слов
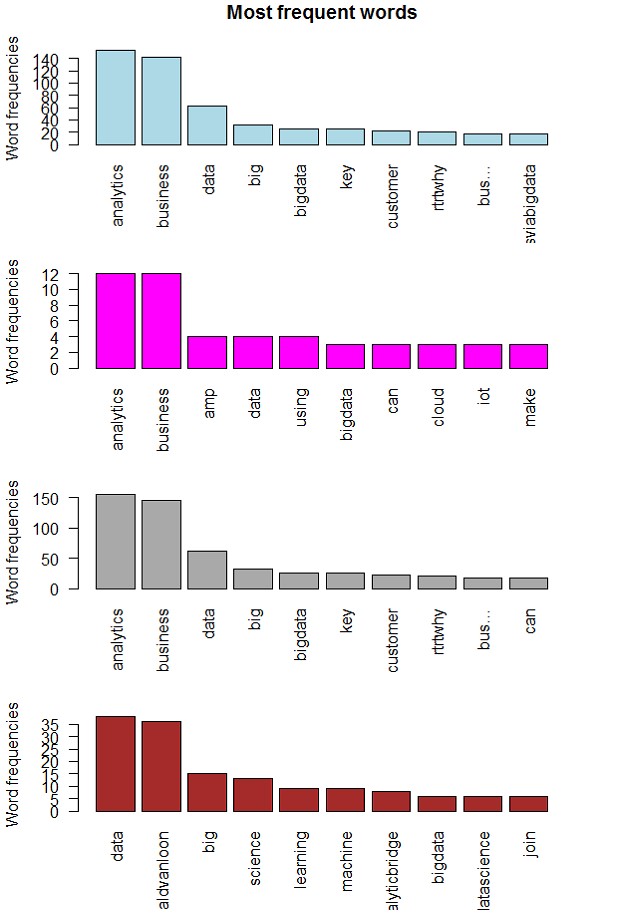
> barplot(d1[1:10,]$freq, las = 2, names.arg = d1[1:10,]$word, col ="lightblue", main ="Most frequent words", ylab = "Word frequencies")
> barplot(d2[1:10,]$freq, las = 2, names.arg = d2[1:10,]$word, col ="magenta", main ="Most frequent words", ylab = "Word frequencies")
> barplot(d3[1:10,]$freq, las = 2, names.arg = d3[1:10,]$word, col ="darkgrey", main ="Most frequent words", ylab = "Word frequencies")
> barplot(d4[1:10,]$freq, las = 2, names.arg = d4[1:10,]$word, col ="brown", main ="Most frequent words", ylab = "Word frequencies")
Рис. 18. Диаграммы наиболее часто встречающихся слов © Источники:
| |
| Категория: Бизнес-аналитика | Добавил: kvn2us (25.04.2017) | | |
| Просмотров: 2432 | |