| Главная » Статьи » Студентам » Бизнес-аналитика |
Загрузить файлНабор данных о фильмах, описание которых содержится в интернет-базе IMDB, находится по ссылке kaggle.com. Если вы заинтересованы в исследовании кинофильмов, тогда перейдите по ссылке и загрузите файл "movie_metadata.csv" . После этого необходимо считать файл в R, используя следующий код:
Таблица данных "Movie" (Кинофильмы)Что внутри?Применение names() позволит посмотреть наименования столбцов созданной таблицы под названием "movie": Чтобы узнать размерность таблицы, следует ввести dim(): или
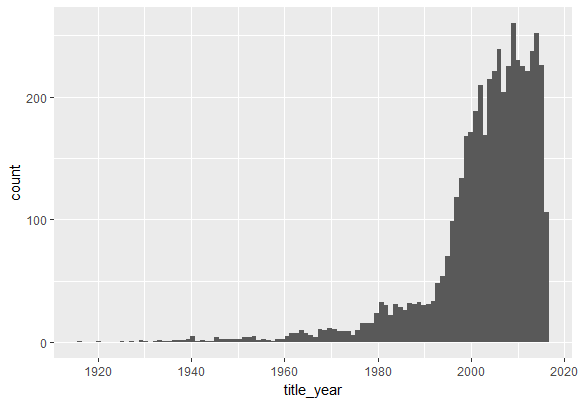
Когда код будет выполнен, консоль программы (Console) покажет структуру таблицы данных. Итак, таблица данных (data frame) состоит из 5043 строк и 28 столбцов. Кроме того, с помощью summary() можно получить немного больше информации о переменных в таблице: ВизуализацияФункция qplot() позволяет получить распределение кинофильмов по годам, как показано ниже на рисунке:
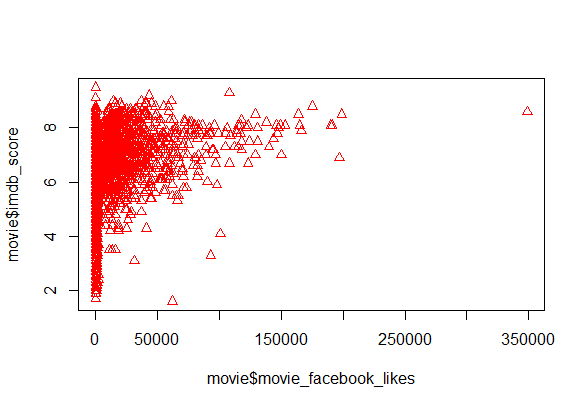
С помощью графиков можно визуально предположить о зависимости между переменными. Рассмотрим график зависимости "imdb_score" от "movie_facebook_likes". Для его построения выполняется функция plot()
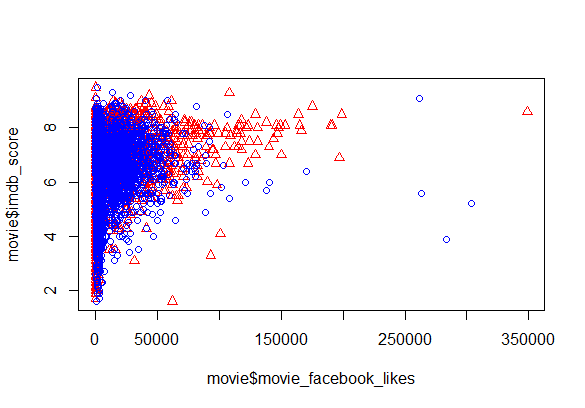
Рассматриваемая таблица данных имеет переменную "cast_total_facebook_likes", которая рассчитывается путем суммирования действий на Facebook (facebook popularity) относительно актерского состава. Добавим ее значения к предыдущему графику посредством такой записи, как:
Получаем новый график (scatter plot), где "cast_total_facebook_likes" отмечены синими кругами.
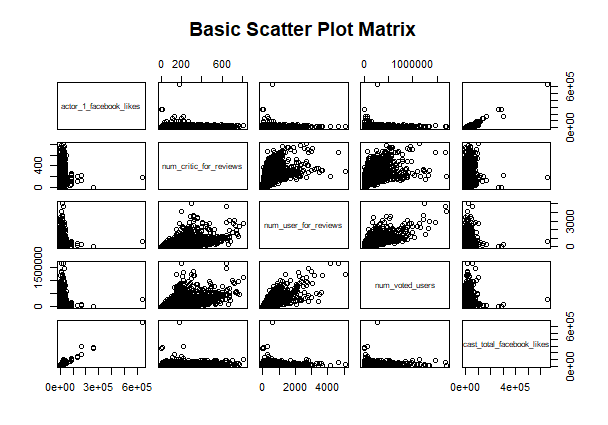
При желании посмотреть связи между разными переменными, можно воспользоваться следующей функцией:
В итоге программа выдает набор графиков
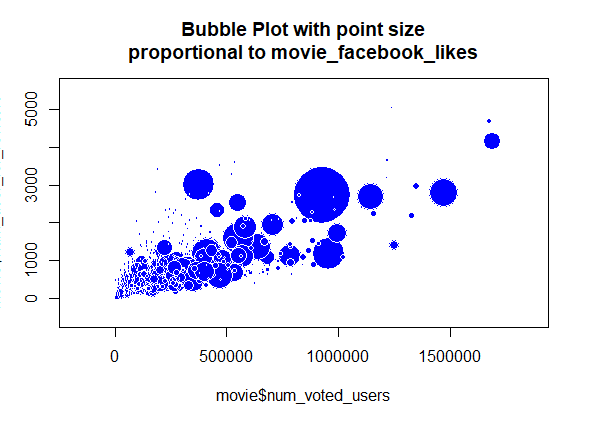
Пузырьковая диаграмма (Bubble plot)Этот параграф статьи посвящен построению пузырьковой диаграммы, которая указывает на то, сколько пользователей проголосовало, и сколько из них просмотрело и предоставило отзыв на фильмы. При этом размер пузырьков пропорционален число отметок "нравится" на Facebook. Чтобы создать данную диаграмму, нужно ввести код R
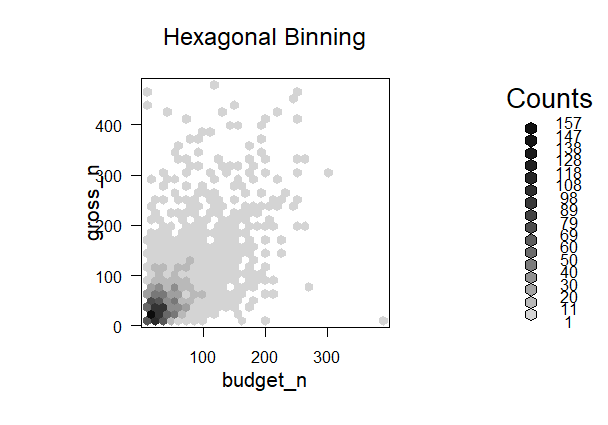
Бюджет и доход. Сотовая диаграммаРассмотрим, как могут быть сгруппированы фильмы по размеру бюджета (budget) и доходу (gross). Графически представим расположение этих групп с помощью "сотовой диаграммы". В ней наблюдения распределяются по гексагональным ячейкам. Ячейки могут отличаются оттенком, по умолчанию, серого или же другого цвета, который ставится в соответствие числу наблюдений в каждой из этих ячеек. Функция summary() показывает, что наименьшим значением для budget является 218, а наибольшим 12215500000. Минимальное значение gross равняется 162, а максимальное - 760505847. В ходе построения диаграммы будут выбраны только те фильмы, которые имеют больше 10 млн. долл. и меньше 500 млн. долл. бюджета и дохода, а также перейдем к "млн. дол." в качестве единицы измерения данных величин.
library(hexbin)
mbg_s<-movie[movie$budget>10000000 & movie$budget<500000000 & movie$gross>10000000 & movie$gross<500000000, ]
with(mbg_s, {
budget_n<-mbg_s$budget/1000000
gross_n<-mbg_s$gross/1000000
bin <- hexbin(budget_n, gross_n, xbins=30, shape=1)
plot(bin, main="Hexagonal Binning")
})
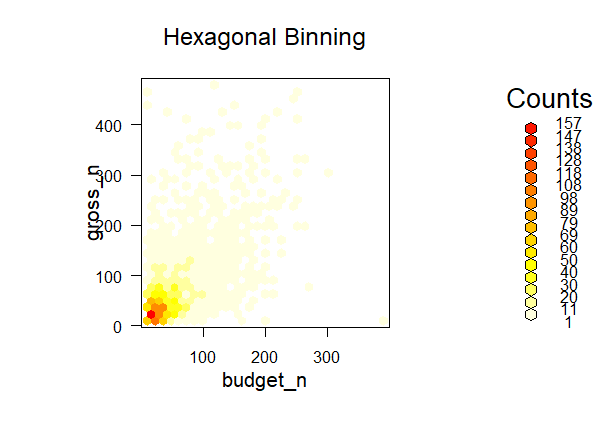
Чтобы получить цветную диаграмму, в функции plot() вносятся дополнительные аргументы
with(mbg_s, {
budget_n<-mbg_s$budget/1000000
gross_n<-mbg_s$gross/1000000
bin <- hexbin(budget_n, gross_n, xbins=30, shape=1)
plot(bin, style="colorscale", colramp = function(n) {rev(heat.colors(n))},
main="Hexagonal Binning")
})
Ниже изображена цветная диаграмма
Можно выбрать альтернативную запись для Color Ramps on Perceptually Linear Scales:
colramp = function(n) {BTC(n, beg=1, end=256)}
colramp = function(n) {LinOCS (n, beg=20, end=250)}
colramp = function(n) {magent (n, beg=240, end=10)}
colramp = function(n) {plinrain(n, beg=240, end=25)}
а также альтернативы цветовых палитр (Color Palettes), используемых для создания вектора n смежных цветов
colramp = function(n) {rainbow(n, s = 1, v = 1, start = 0, end = max(1, n - 1)/n, alpha = 1))}
colramp = function(n) {terrain.colors(n, alpha = 1)}
colramp = function(n) {topo.colors(n, alpha = 1)}
colramp = function(n) {cm.colors(n, alpha = 1)}
Для построения сотовой диаграммы, такой как и на предыдущем рисунке, можно применять функцию hexbinplot():
hexbinplot(gross_n~budget_n, mbg_s, aspect = 1,
colramp = function(n) {rev(heat.colors(n))})
Чтобы отобразить кинофильмы точками на графике в зависимости от их бюджета и дохода, используя при этом прозрачные маркеры, следует записать:
col_bg <- adjustcolor("darkblue", alpha.f = 0.2)
plot(budget_n, gross_n,
main = "Budget and Gross of Movies,\n transparent markers",
pch = 19, cex = 1.25, xlab = "Budget", ylab = "Gross",
col = col_bg)
Тогда график имеет вид
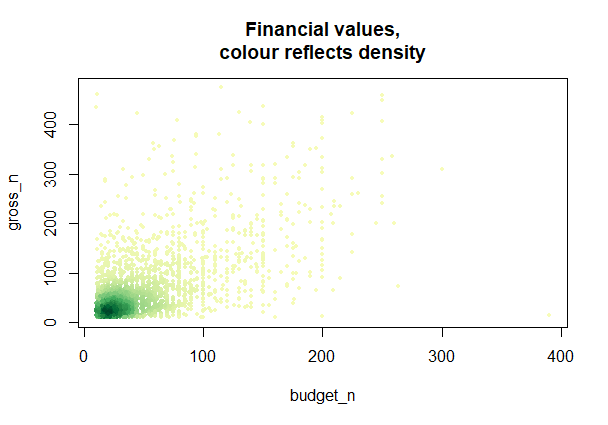
Еще один способ создания такого графика заключается в изображении через цвет плотности их распределения library(RColorBrewer) ramp_col <- colorRampPalette(brewer.pal(9,"YlGn")[-1]) col_density <- densCols(budget_n, gross_n, colramp = ramp_ylgn) plot(budget_n, gross_n, col = col_density, pch = 19, cex = 0.6, main = 'Financial values,\ncolour reflects density') В конечном итоге получим график
Очистка данныхНедостающие данные (NA)При необходимости работы только с заполненными экземплярами (complete cases), прежде всего, нужно выявить, отсутствуют ли данные (missing data), т.е. проверить наличие значений NA в "movie": и / или
и / или и / или Действительно, в "movie" имеются значения NA. Поэтому создадим на основе имеющейся таблицы данных новую с именем "imdbdf". Новая таблица данных имеет ту же шапку и размерность, что и предыдущая. Далее нужно исключить из таблицы записи, в которых по крайней мере есть одно значение NA. Получили очищенную таблицу с тем же именем "imdbdf", но уже с меньшим числом строк, равным 3801: Более того, имеет смысл проверить таблицу на наличие дублирующих экземпляров и исключить их:
Таким образом таблица данных сократилась до 3768 строк. Выбор переменныхВ случае, если не требуется работа со всеми переменными (столбцами), а только с некоторыми из них, то можно указать нужные: Проверим, сколько строк и столбцов насчитывается в модифицированной таблице:
РанжированиеОпределим рейтинг каждого актера по оценке (score) IMDb. Для этого подключим пакет "plyr" и применим его функцию "ddply", что позволит рассчитать среднее значение рейтинга и его стандартную ошибку (SE) по каждому актеру. "ddply" разбивает "imdbdf" на меньшие таблицы по переменной "actor_1_name". После этого вычисляет среднюю оценку (IMDB score), стандартную ошибку SE и число наблюдений N по каждой таблице, содержащей данные об отдельном актере. Следует отметить, что
В итоге, функция "ddply" сводит меньшие таблицы и полученные вычисления по ним в новую таблицу данных (data frame) "ratingdat", которая уже состоит из 1457 строк и 4 столбцов. Но, если просмотреть вновь созданную таблицу, то видны NA. Так, используя head(ratingdat) или ratingdat[1:50, ], обнаруживаем, что NA присутствуют в столбце "SE" напротив N = 1. Исходя из требований к вычислениям статистических характеристик и намерением выделить популярных актеров с высоким рейтингом, осуществим выбор тех экземпляров, в которых N>=15.
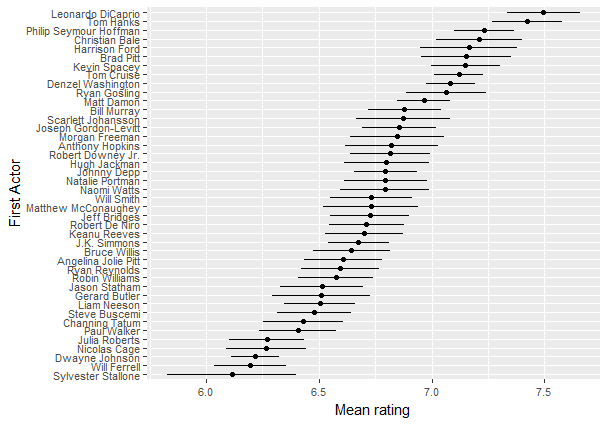
Упорядочим актеров по среднему рейтингу (ordered factor)
Следующим шагом является создание графика главных актеров, упорядоченных по показателю среднего рейтинга. Но прежде, чем сделать это, нужно подключить такие add-onn пакеты, как
Теперь к построению графика с помощью следующей записи команд:
Получаем график упорядоченных рейтингов актеров
Новая таблица - data frameСоздание "imdbdf2"Новая таблица данных основывается на "movie":
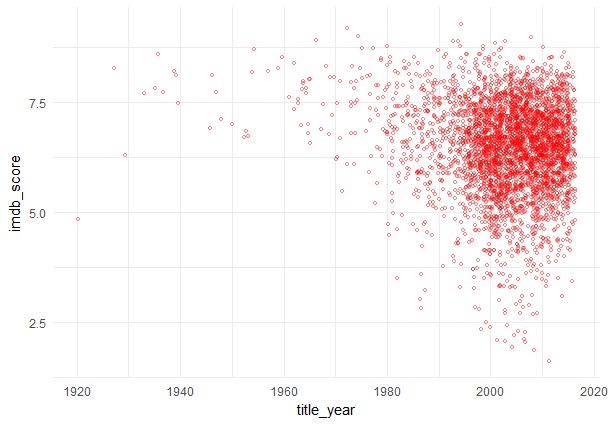
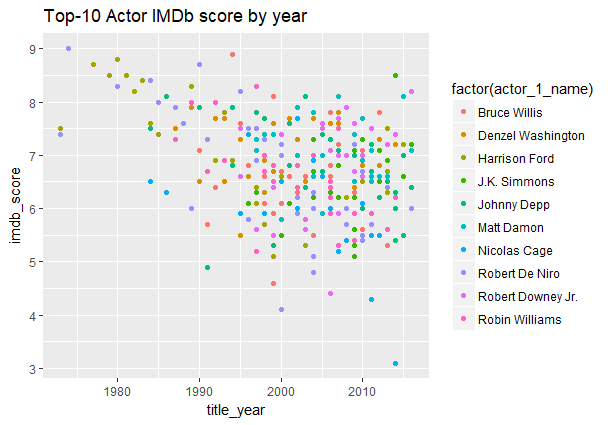
Как видно, созданная таблица данных «imdbdf2» не содержит повторы в строках и экземпляры с отсутствующими значениями (NA). Последнее было обеспечено за счет реализации функции na.omit(). Вся таблица состоит из 3701 строки и 6 столбцов: «actor_1_name», «movie_title», «title_year», «gross», «imdb_score», «plot_keywords». Рейтинги фильмов по годамНа представленном ниже рисунке изображено распределение рейтингов фильмов (IMDb scores) по годам.
Построение данного графика достигается посредством выполнения следующего кода:
Топ-10 актеров по числу главных ролейВыбор топ-10Определим, в скольких кинофильмах, собранных в таблице "imdbdf2", каждый из актеров сыграл главную роль. Полученные значения перенесем в отдельную таблицу "actors", а ее столбцам присвоим названия "Actor" и "No_movies", т.е. имя актера и число фильмов, в которых он сыграл главную роль:
Созданная таблица состоит из 1457 строк, а сумма по 2-му столбцу, которая показывает количество всех кинофильмов, равняется 3701, что соответствует числу строк в "imdbdf2":
Упорядочим актеров в "actors" по количеству кинофильмов с их участием по убыванию:
Отберем 10 актеров с наибольшим числом сыгранных главных ролей. Обозначим эту выборку через "actorsTop10":
Шапка "actorsTop10" для первых трех строк имеет вид:
Первая десятка актеров насчитывает 294 кинофильма, что составляет 7,9 % от общего количества кинофильмов в "imdbdf2":
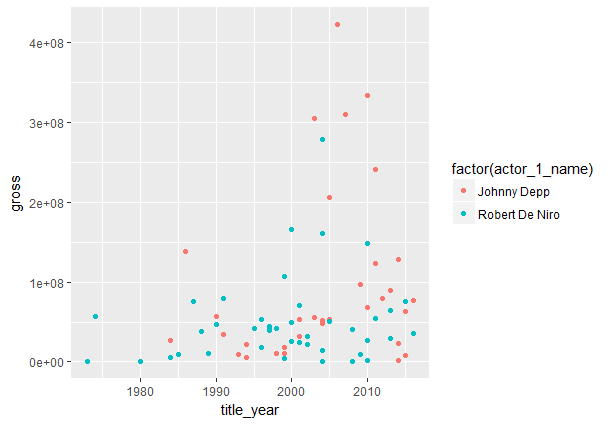
Сравнение по 2 первым актерамДалее осуществим выборку записей из "imdbdf2", в которых по столбцу "actor_1_name" присутствуют актеры из "actorsTop10", например, Роберт Де Ниро и Джонни Депп:
Полученные таким образом таблицы состоят из 80 строк и 6 столбцов. На основе графика сравним указанных актеров по динамике дохода кинофильмов с их участием:
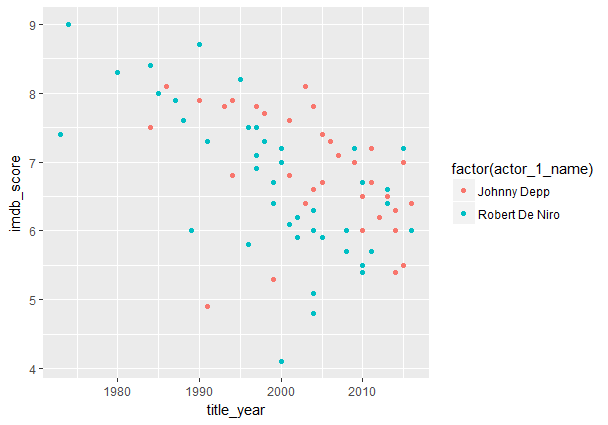
Чтобы посмотреть динамику рейтинговой оценки IMDb кинофильмов, главную роль в которых сыграл Роберт де Ниро или Джонни Депп, выполним:
Чтобы получить больше сведений, к примеру, о Роберте Де Ниро, достаточно ввести:
В таблице ниже содержатся сведения о Роберте Де Ниро и Джонни Деппе, занимающих 1-ю и 2-ю позицию в Топ-10 по числу сыгранных главных ролей. Из таблицы видно, что Роберт Де Ниро сыграл в 42 фильмах, тогда как Джонни Депп в 34. Фильм с максимальной оценкой, равной 9, относится к Де Ниро. По показателям дохода преимущество у группы кинофильмов с Дж. Депп. Так, средний доход фильмов, в которых снялся Де Ниро, составляет чуть более 50 млн. долл. От проката фильмов с участием Деппа в среднем получено почти 94,4 млн. Таблица. Характеристика кинофильмов с Р. Де Ниро и Дж. Деппом в главной роли
Анализ топ-10Сформируем выборку кинофильмов по всем актерам, вошедшим в десятку лучших по числу сыгранных главных ролей:
Проверим, имеет ли "proba" повторяющиеся экземпляры, и исключим их из данной таблицы:
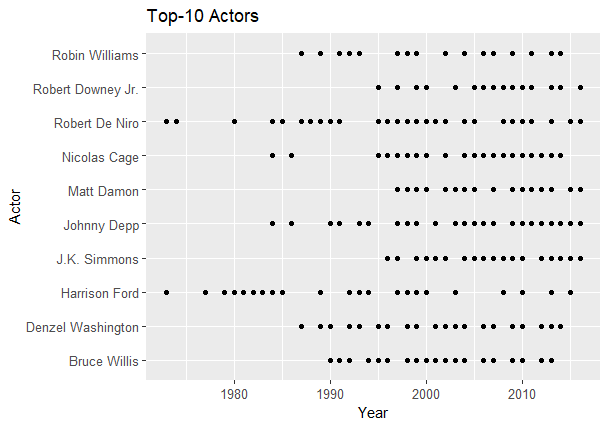
Таким образом, в окончательном варианте новая таблица содержит 294 строки. Чтобы посмотреть, в каком году снялся в главной роли каждый из данных актеров, введем:
Построим график оценок по годам для десяти актеров:
или
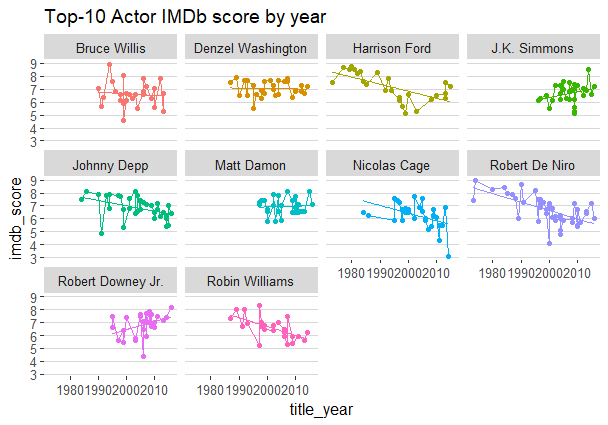
Динамика рейтингов фильмов по годам и отдельно по каждому актеру задается посредством команд:
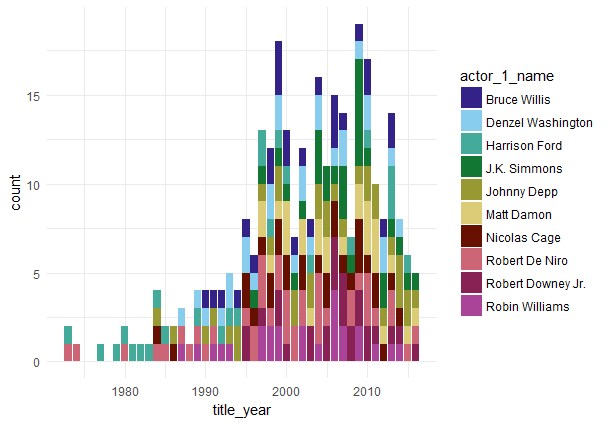
Возможно, будет полезным изучить суммарный рейтинг отобранных кинофильмов по годам с учетом вклада каждого из актеров, вошедших в десятку:
Вывод: кто же лучший?Исходя из средней оценки кинофильмов (не менее 15-ти), в которых актер сыграл главную роль, лидером выступает Леонардо ДиКаприо, а следом за ним Том Хэнкс.
Представим упорядоченный по средней оценке список актеров, вошедших в Топ-10 по числу главных ролей:
В тоже время Топ-10 актеров по числу кинофильмов, в которых ими сыграна главная роль, имеет следующий вид:
Итак, получен список 18 претендентов на звание лучшего актера. Далее стоит вопрос о том, какую применить методику для выбора наилучшего. Источники
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Категория: Бизнес-аналитика | Добавил: kvn2us (01.09.2017) | | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Просмотров: 1826 | | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||