| Главная » Статьи » Студентам » Бизнес-аналитика |
Регрессионный анализ
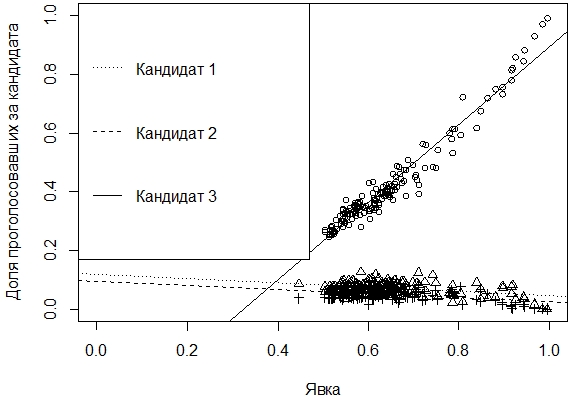
Часть 2. Сравнение регрессийОпределение нескольких линейных моделейНередко требуется сравнить несколько регрессий на основе одних и тех же данных. Это подтверждается примером о результатах выборов, когда нужно проанализировать соответствие между процентом избирателей, проголосовавших за данного кандидата, и процентом явки на конкретном избирательном участке. Различие электоратов приводит к разным отношениям между указанными показателями. Возьмем данные из текстового файла, содержащего данные о результатах голосования за трех кандидатов по множеству участков. > vybory <- read.table("vybory.txt", h=TRUE) 'data.frame': 153 obs. of 7 variables: Присоединим таблицу данных для того, чтобы с ее столбцами работать как с независимыми переменными: > attach(vybory) Вычислим доли проголосовавших за каждого кандидата и явку > share<-cbind(KAND.1, KAND.2, KAND.3) / IZBIR Рассчитаем корреляцию между явкой и долей > cor(att, share) Можно предположить небольшую корреляцию для первых 2 кандидатов и ее отличие от корреляции для 3-го кандидата. Построим модели регрессии по всем кандидатам и выведем сведения о них > lm.1 <- lm(share[,1] ~ att) [[1]] Call: Residuals: Coefficients: Residual standard error: 0.01929 on 151 degrees of freedom [[2]] Call: Residuals: Coefficients: Residual standard error: 0.0169 on 151 degrees of freedom [[3]] Call: Residuals: Coefficients: Residual standard error: 0.03684 on 151 degrees of freedom Далее представим результаты регрессионного анализа графически > plot(share[,3] ~ att, xlim=c(0,1), ylim=c(0,1), xlab="Явка", ylab="Доля проголосовавших за кандидата") Графически предположение о различии модели регрессии по 3-му кандидату от моделей по первым двум подтверждается (рис. 1).
Рис. 1. Линейные модели регрессии по каждому кандидату В регрессионном анализе встречаются категориальные переменные (categorical variable), которые имеют значения «да» / «нет», «женский» / «мужской» и т.п. В примере о выборах данные можно представить таким образом, что категориальной переменной становится «кандидат». Для того, чтобы статистически сравнить регрессии с категориальными переменными (факторами, предикторами) применяется метод анализа ковариаций – ANCOVA.
Создание таблиц данных с категориальными переменнымиСоздадим новую таблицу данных, в которой 1 столбец – это явка, и назовем его «javka»; 2-й – доля («dolja»), а 3-й – фактор с именами кандидатов («kand»). > vybory2 <- cbind(att, stack(data.frame(share))) 'data.frame': 459 obs. of 3 variables: Рассмотрим алгоритм создания новой таблицы “vybory2”. Изначально имеем таблицу “share” – доли проголосовавших за каждого кандидата по всем избирательным участкам. > head(share,3) KAND.1 KAND.2 KAND.3 После выполнения stack() получаем таблицу, в которой один столбец – значения доли, а второй – имя кандидата. Сначала выводятся данные по 1-му кандидату, потом – по 2-му и, наконец, все значения по 3-му. >head(stack(data.frame(share)),3) values ind Далее в полученную таблицу добавили столбец ”att” – явка, в котором значения расположены таким же образом – сначала по 1-му кандидату, потом по 2-му, и, наконец, по 3-му. Поэтому строк (наблюдений) в новой таблице насчитывается 459 шт. > head(vybory2, 3) javka dolja kand После создания новой таблицы переходим к анализу. При этом будем использовать две функции lm() и aov(). 1. lm()> ancova.v <- lm(dolja ~ javka * kand, data=vybory2) Call: Residuals: Coefficients: Residual standard error: 0.02591 on 453 degrees of freedom
отклик ~ воздействие * фактор, где звездочка «*» обозначает, что надо проверить одновременно отклик на воздействие, отклик на фактор и взаимодействие между воздействием и фактором. Следует отметить, что линейная регрессия использует более простую формулу «отклик ~ воздействие». В нашем случае откликом была доля проголосовавших, воздействием – явка, а фактором – имя кандидата. Больше всего нас интересовало, правда ли, что имеется сильное взаимодействие между явкой и третьим кандидатом. Полученные результаты (см. строку javka:kandKAND.3) доказывают значимость этого взаимодействия. 2. aov()С взаимодействием фактора и предиктора > ancova.v2 <- aov(dolja ~ javka * kand, data=vybory2) Df Sum Sq Mean Sq F value Pr(>F) Из представленных результатов видно, что значимыми являются и воздействие javka, и фактор kand, и их взаимодействие, поскольку P-значение меньше 0,05. Без взаимодействия фактора (категориальной переменной) и предиктора > ancova.v3 <- aov(dolja ~ javka + kand, data=vybory2) Df Sum Sq Mean Sq F value Pr(>F) СравнениеСравним две модели (с и без взаимодействия фактора и предиктора), чтобы окончательно убедиться, является ли взаимодействие на самом деле статистически значимым. Для этого воспользуемся anova() > anova(ancova.v2,ancova.v3) Analysis of Variance Table Model 1: dolja ~ javka * kand Поскольку F-значение намного больше 1, а Р-значение меньше 0,05, то приходим к выводу, что взаимодействие является значимым. К тому же, сумма квадратов остатков (RSS) для модели с взаимодействием меньше, чем для модели без него. В дополнение можно посмотреть на результаты anova() для ancova.v2 ancova.v3 по-отдельности.
| |
| Категория: Бизнес-аналитика | Добавил: kvn2us (02.04.2017) | | |
| Просмотров: 2370 | |